每段信息尽量给出来源,没有详细总结的可以点进去看。图片尽量使用外链保留原链接,无法加载请挂梯子。
目录
LLM基础知识
占用显存
- 推理:
- 一个 float32 型数字占用 4 Byte,所以 1B 参数模型全精度部署占用 4e9 Bytes = 4 GB. 同理,半精度 fp16/bf16 每B参数占用2GB,int8 每B占用1GB,int4 0.5GB
- 前向计算开销:通常在模型权重的20%左右,因此总的显存占用在1.2倍的模型显存左右
- 训练:
- fp32所占的显存过大,fp16的精度往往达不到期望的程度,因此普遍使用混合精度训练:采用fp32、fp16和混合精度训练时,一般保存权重的时候是 fp16/bf16,fp32只用在累加算子上,防止误差的累积。
- 需要加载的有模型权重参数、梯度值、优化器状态(如Adam需要维护主权重、一阶动量和二阶动量,并且采用fp32形式保存参数,所以=3*4*参数量 Bytes)、激活状态()
- 强化学习训练:
- 根据算法不同还需要加载、更新 Reward Model、Reference Model等
大模型训练推理显存计算简介 - 知乎
https://zhuanlan.zhihu.com/p/624740065
熵与KL散度
信息熵(Entropy, $ H $ ) 衡量的是一个随机变量的不确定性。对于一个离散概率分布 $ P(X) $ ,其熵定义为:
其中, $ P(x) $ 是随机变量 $ X $ 取值 $ x $ 的概率, $ \log $ 通常以 2 为底(单位为比特)或以 $ e $ 为底(单位为纳特,nats)。
交叉熵(Cross-Entropy, $ H(P, Q) $ ) 衡量的是当实际分布为 $ P $ 时,用分布 $ Q $ 进行编码的期望信息量。定义如下:
如果 $ P = Q $ ,则交叉熵等于信息熵( $ H(P, P) = H(P) $ ),否则 $ H(P, Q) \geq H(P) $ 。
KL 散度(Kullback-Leibler Divergence, $ D_{KL}(P \parallel Q) $ )(或相对熵)衡量的是两个概率分布 $ P $ 和 $ Q $ 之间的差异,定义为:
KL 散度可以通过交叉熵与信息熵的关系表示:
这表明,KL 散度衡量了使用分布 $ Q $ 进行编码相比于最优分布 $ P $ 额外的编码代价(即冗余信息量)。由于交叉熵总是大于等于信息熵,因此 KL 散度总是非负的,即 $ D_{KL}(P \parallel Q) \geq 0 $ ,当且仅当 $ P = Q $ 时取 0。
Transformer
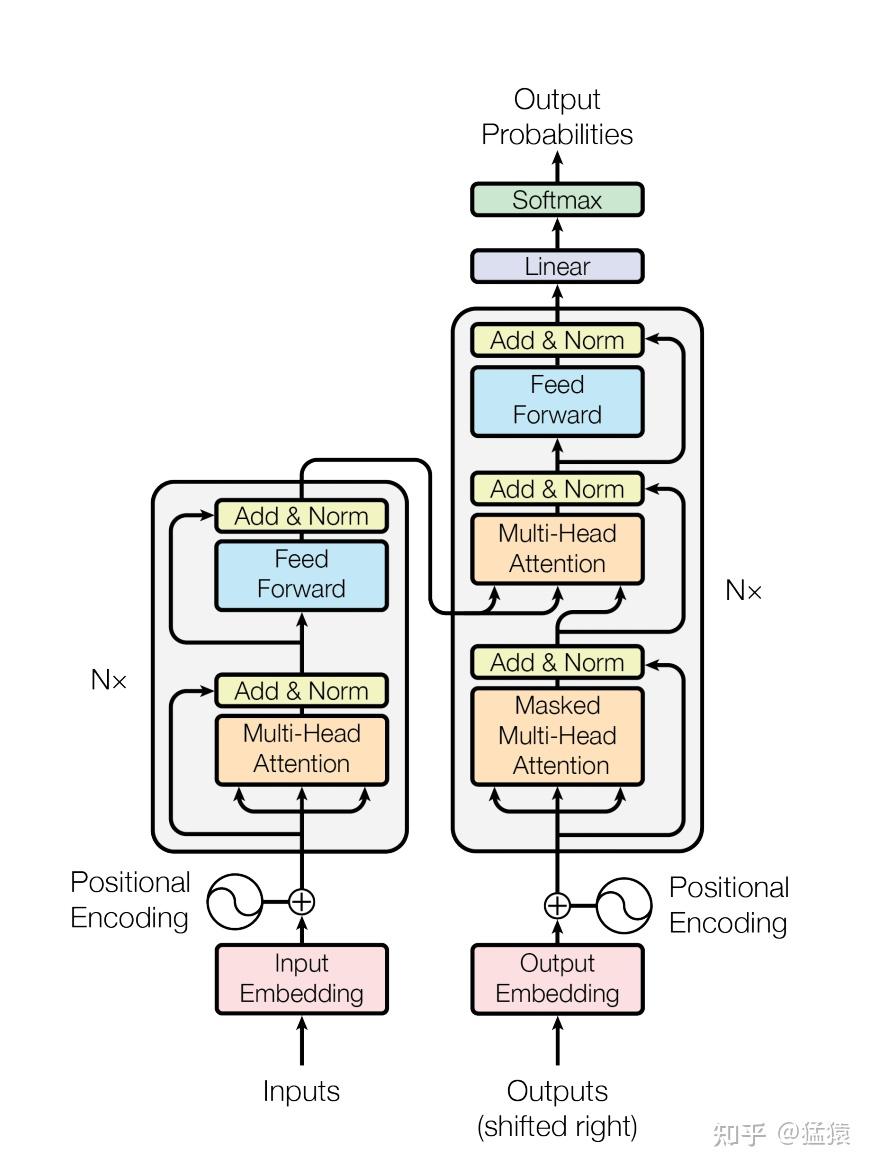
LLM可视化结构参见:https://bbycroft.net/llm
- Encoder:
- 由多层堆叠的 Self-Attention 和 Feed-Forward Network (FFN) 组成。
- 输入流程: 输入嵌入 → 位置编码 → 多头自注意力 → Add & LayerNorm → FFN → Add & LayerNorm。
- Decoder:
- 在 Encoder 基础上增加 Encoder-Decoder Attention 层。
- 自注意力层使用 Masked Attention(防止看到未来信息)。
- 输入流程: 输入嵌入 → 位置编码 → 掩码多头自注意力 → Add & LayerNorm → 编码器-解码器注意力 → Add & LayerNorm → FFN → Add & LayerNorm。
自注意力机制通过计算输入序列中每个位置与其他位置的 Attention Scores ,动态捕捉全局依赖关系。具体步骤:
- 将输入向量通过线性变换生成Query(Q)、Key(K)、Value(V)。
- 计算注意力分数:
其中 $ d_k $ 是Key的维度,用于缩放梯度。 - 多头注意力(Multi-Head)将Q、K、V分割到多个子空间并行计算,增强模型对不同语义关系的捕捉能力。
具体实现
- 残差连接:
- 作用:保留输入信息,缓解梯度消失问题,提高训练稳定性。
- FFN:
- 作用:Self-Attention 主要负责捕捉长距离依赖关系,但它本身是线性的,缺乏强大的特征提取能力。FFN 提供非线性变换,提高特征表达能力。对attention score先升维后降维让模型更好地整理、精炼已经被注意力提取的信息
- self attention是token mixer。FFN是channel mixer。也就是说attention会混合多个token的信息来提取特征,但每个channel(特征维度)保持独立。而FFN不混合token,而是混合不同的feature channel。两种计算操作不同的层面来提取特征,相得益彰。
- Layer Normalization (LN):
- 对同一样本的所有特征进行归一化。
- 作用:稳定训练,防止分布偏移,提高模型收敛速度。
- 公式:
其中 $ \mu, \sigma $ 是样本的均值和标准差, $ \gamma, \beta $ 是可学习参数。
- 其他归一化方式:
- Root Mean Square Layer Normalization (RMSNorm): 在 LN 的基础上不再计算均值,只计算均方根来衡量数据的平均幅度,加快计算速度,增加训练效率。当 $ \mu = 0 $ 时,LN == RMSNorm
- Batch Normalization (BN): 对不同样本的同一特征归一化,适合固定长度的数据(如图像)。
- encoder decoder 区别:
- Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作;第二个 MHA 根据 Encoder 的输出 C 计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
常见问题
为什么要将 $ QK^T $ 进行scale
$ K^T $ 维度为 $ d_k $ , $ d_k $ 很大, $ QK^T $ 点乘结果方差过大,让softmax函数退化成argmax,导致梯度消失。
为什么要用 $ \sqrt{d_k} $ 进行scale
这是 $ QK^T $ 的方差,这样操作可以把它归一化成服从正态分布的量。
为什么用 LN 而非 BN?
- BN 不适用于不定长序列,但 NLP 中序列长度可变。LN 不受批次、序列长度影响。
- BN 会损失信息差异性,在 batch 中归一化,会抹平不同样本差异,而训练 LLM 需要不同信息的差异。
为什么要用MHA
一个 attention head 可能会过度将注意力集中于自身的位置,MHA 的输出包含不同子空间的编码表示信息,可以学到多维度的特征信息,从而增强模型的表达能力。同时 MHA 可并行计算,便于 Scale Up,提升计算效率。
与RNN相比的优势:
- 并行性:自注意力可同时计算所有位置的关联,便于Scale Up;而RNN是串行的,需逐步处理。(encoder的MHA和FFN是并行的,decoder在训练时可以,但由于mask的存在,推理阶段是串行的)
- 长距离依赖:无论序列长度,任意两位置的交互只需一步计算,避免RNN的梯度消失/爆炸问题。
为什么现在的LLM都是Decoder only的架构?
- Decoder架构主要是是为了预测下一个输出token,而这个任务更适配大模型的上下文学习。
- Pipeline Parallel 流水并行的训练并行度最高,它的条件是需要一个规整对称的、线性顺序的网络结构,而 Decoder-Only 的架构最为简单,方便于 Scale Up,基于 Scaling Laws 的实际训练成本最低。 Encoder-Decoder 和 Encoder-Only 架构的优势无法弥补训练成本的大幅提升。
Encoder 架构的问题:
- Encoder 的 attention 是 双向的,不能像 decoder 那样顺序处理 → 导致需要一次性处理整个输入 → 并行切不动。
- Encoder-decoder 通常等 encoder 处理完所有输入后,decoder 才能开始 → 串行依赖严重,无法并发。
- Encoder-decoder 有两个不同网络 → 不对称 → 切分困难,资源利用率低。
初始化方法
- Xavier/Glorot 初始化: 适用于 Sigmoid/Tanh 激活函数,使得前向传播时信号方差保持稳定,方差为 $ 2 / (n_{\text{in}} + n_{\text{out}}) $ 。
- He 初始化: 适用于 ReLU,保证前向和反向传播时信号不易消失或爆炸,方差为 $ 2/n_{\text{in}} $ 。
- 正交初始化: 保持矩阵正交性,防止梯度爆炸/消失。
全零初始化的缺陷
- 对称性问题: 所有神经元输出相同,反向传播时梯度对称,导致无法学习差异特征。
位置编码与位置外推
对于不带Attention Mask的纯Attention模型,它是全对称的。因此self-attention的运算是无向的,token的位置是无法分辨的信息,因此要给每个位置都加上一个位置编码向量。
位置外推能力是指模型处理超过其训练序列长度的输入序列的能力,从而能够在扩展序列上保留上下文和一致性,即 Train short, test long.
正弦函数位置编码
vanilla transformer使用正弦函数位置编码
- 绝对性: 每个token的向量唯一(每个sin函数的频率足够小)
- 位置向量的值是有界的,且位于连续空间中。模型在处理位置向量时更容易泛化,即更好处理长度和训练数据分布不一致的序列(sin函数本身的性质)
- 相对性: 不同的位置向量是可以通过一个旋转矩阵的线性转换得到的,即
- 距离衰减性: 两个位置编码的点积(dot product)仅取决于偏移量 $ △t $ ,内积越小,两个点距离越远
存在的问题:
- 对称性: 位置编码的点积是无向的,即 虽然位置向量的点积可以用于表示距离(distance-aware),但是它却不能用来表示位置的方向性(lack-of-directionality)
- 当位置编码随着input被喂进attention层时,采用的映射方其实是: 所以进入attention层之后,内积的距离意识(distance-aware)的模式遭到了破坏。
Transformer学习笔记一:Positional Encoding(位置编码) - 知乎
ALiBi
ALiBi工作于attention计算过程中:在计算attention score的时候,会对之前位置的分数按照与当前位置的差距进行不同程度的惩罚。具体来说,在qk点积时,增加携带位置信息的惩罚$softmax(q_iK^T+m\left[-(i-1),…,-2,-1,0\right])$
RoPE
RoPE是当前大模型标配的位置编码方式。这种编码不是作用在embedding的输入层,而是作用在与Attention的计算中。它使用旋转矩阵对绝对位置进行编码,同时在自注意力公式中结合了明确的相对位置依赖性。
具体来说,RoPE首先计算query矩阵和key矩阵,接着将每个位置的query和key向量的元素按照两两一组应用旋转变换,最后再利用注意力分数对value矩阵进行加权。
https://kexue.fm/archives/8265
https://zhuanlan.zhihu.com/p/863378538
其他长上下文方法
由于 KV cache 的存在,输入文本越长占用显存越多。在位置编码方式不变的前提下,可以通过模型优化来降低使用的显存,从而容纳更多上下文。具体见各种优化章节。
MoE
- 与稠密模型相比, 预训练速度更快
- 与具有相同参数数量的模型相比,具有更快的 推理速度
- 需要 大量显存,因为所有专家系统都需要加载到内存中
- 微调难度更大
因此为开源社区打造的 LLM 更倾向于稠密模型,为大公司打造的更倾向于 MoE。
而且稠密模型可以更新成 MoE,反之不行

混合专家模型主要由两个关键部分组成:
- 稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干”专家”(例如 8 个),通常是前馈网络 (FFN),也可以是更复杂的网络结构,甚至可以是 MoE 层本身
- 门控网络或路由: 这个部分用于决定哪些令牌 (token) 被发送到哪个专家。路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。

流程:
- Gating / Router:
如果所有的令牌都被发送到只有少数几个受欢迎的专家,那么训练效率将会降低。为了缓解这个问题,引入了一个 辅助损失,旨在鼓励给予所有专家相同的重要性。这个损失确保所有专家接收到大致相等数量的训练样本,从而平衡了专家之间的选择。 - Dispatch: 将输入token根据上一步得到的权重分发给对应的专家FFN
- Combine: 最终输出是各个专家的输出根据 gating score 的加权求和
稀疏混合专家模型 (MoE) 适用于拥有多台机器且要求高吞吐量的场景。在固定的预训练计算资源下,稀疏模型往往能够实现更优的效果。相反,在显存较少且吞吐量要求不高的场景,稠密模型则是更合适的选择。
混合专家模型(MoE)详解
Mixture of Experts in LLMs Explained
各种优化
- KV cache
- KV缓存通过存储之前生成的tokens的键向量(key vector)和值向量(value vector),避免了重复计算。当生成新token时,只需使用缓存中的键向量和值向量进行计算。这是一个用存储换效率的方案。从数学来说,KV缓存需要O(N^2)的空间复杂度。
- 好处是计算复杂度从token长度的平方降低到线性,显著提高了推理效率。在处理长序列或大批次数据时,效果尤其显著。
- 坏处是KV矩阵占用的缓存大小与token长度的平方成正比:当token长度增加时,GPU缓存占用急剧上升。
- MHA MQA GQA (三字狂魔)
- MLA
- Linear Attention
- 注意力机制复杂度 n^2 的来源:由于有 softmax 存在,需要先计算 Q×K^T 得到一个 n*n 的矩阵,再右乘一个 n×d 大小的 V ,因此时间复杂度 O(n)= kn^2。如果去掉 softmax 就可以先算 K^T×V ,大小 d×n 的 乘 n×d 的 得到 d×d 的矩阵,再左乘 n×d 的 Q, 时间复杂度 O(n)= nk^2
- 线性Attention的探索:Attention必须有个Softmax吗? - 科学空间|Scientific Spaces
- Sparse Attention
- 只计算距离当前相对距离不超过k的、相对距离为k,2k,3k,…位置的注意力分数,让 Attention 具有“局部紧密相关和远程稀疏相关”的特性,因为真正需要密集的长程关联的任务事实上是很少的。
- https://spaces.ac.cn/archives/6853#Sparse%20Self%20Attention
- 量化、压缩模型

评估
Perplexity PPL 困惑度(预训练阶段)
对于一个随机变量,
对于两个分布之间,
其中, $ H(p_r, p_\theta) $ 是真实分布 $ p_r $ 和模型分布 $ p_\theta $ 之间的交叉熵:
因为我们只有给定语料 $ S $ 没有真实分布 $ p_r $ ,所以我们假设 $ p_r = 1/n $ ,因此得到
实际计算时为了节省计算量不计算n个,采用滑动窗口: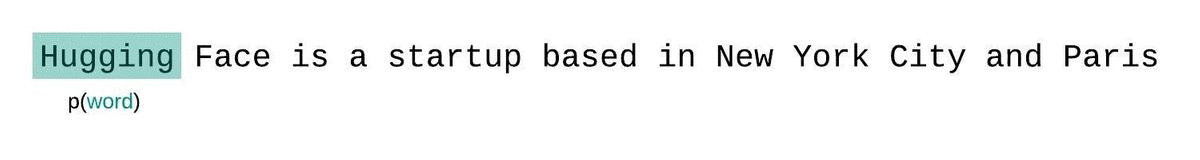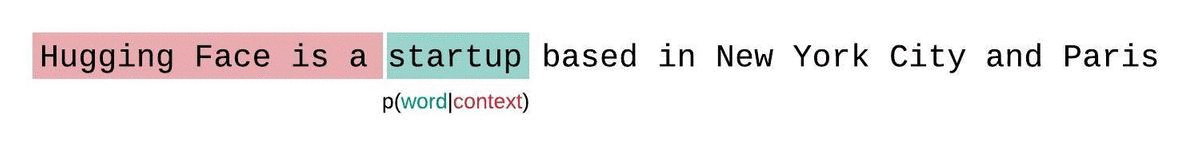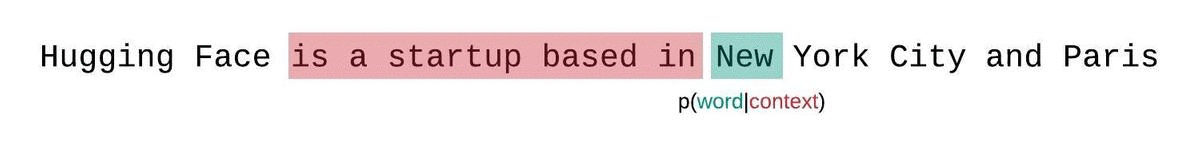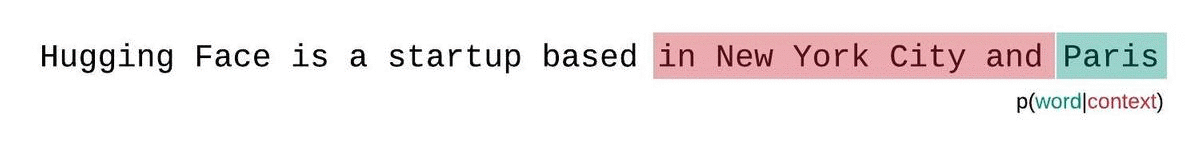
BLEU
decoding 策略
- top-p: 仅从累计概率达到 p 的候选 token 中进行采样,去掉尾部低概率 token。
- top-k: 仅从概率最高的 K 个 token 中随机采样,忽略其他候选 token。
- temperature: $ P_i = \frac{\exp(\frac{\log P_i}{T})}{\sum \exp(\frac{\log P_j}{T})} $
- $ T > 1 $ :概率分布变得更均匀,增加随机性,文本更有创造力,但可能不连贯。
- $ T < 1 $ :概率分布更陡峭,模型更倾向于选择最高概率的 token,使输出更确定,但可能缺乏多样性。
- $ T=0 $ 时,等价于贪心(Greedy Decoding)。
- beam-search: 在每一步保留 B(beam size)个最有可能的序列,并扩展它们,最终选择得分最高的序列。适用于翻译等需要高质量、确定性的任务,但可能导致文本缺乏多样性。
- Best-of-N: 生成 N 个候选文本序列,然后选择得分最高的一个作为最终输出。
- Majority Vote: 生成多个候选文本序列,对它们进行投票,选择出现最多的 token 作为最终输出。
LoRA
大型预训练模型参数量巨大,但在特定下游任务上,并不是所有参数都需要更新。LoRA 借鉴了这一思想,提出了一种低秩分解(low-rank decomposition)的方法来更新模型参数,从而大幅减少需要微调的参数量。
具体来说,对于预训练模型中的任何一个参数矩阵 $W_0 \in \mathbb{R}^{n \times m}$,LoRA 不直接对 $W_0$ 进行微调,而是引入一个低秩矩阵的增量 $\Delta W$:
其中 $A \in \mathbb{R}^{n \times r}$ 且 $B \in \mathbb{R}^{r \times m}$,而 $r$ 是一个非常小的秩(rank)。
因此,微调后的新矩阵 $W$ 可以表示为:
在微调过程中,我们固定原始的 $W_0$ 参数,只训练 $A$ 和 $B$ 这两个小矩阵。由于秩 $r$ 远小于 $n$ 和 $m$,所以 $A$ 和 $B$ 的总参数量远小于 $W_0$ 的参数量,从而实现了高效的微调。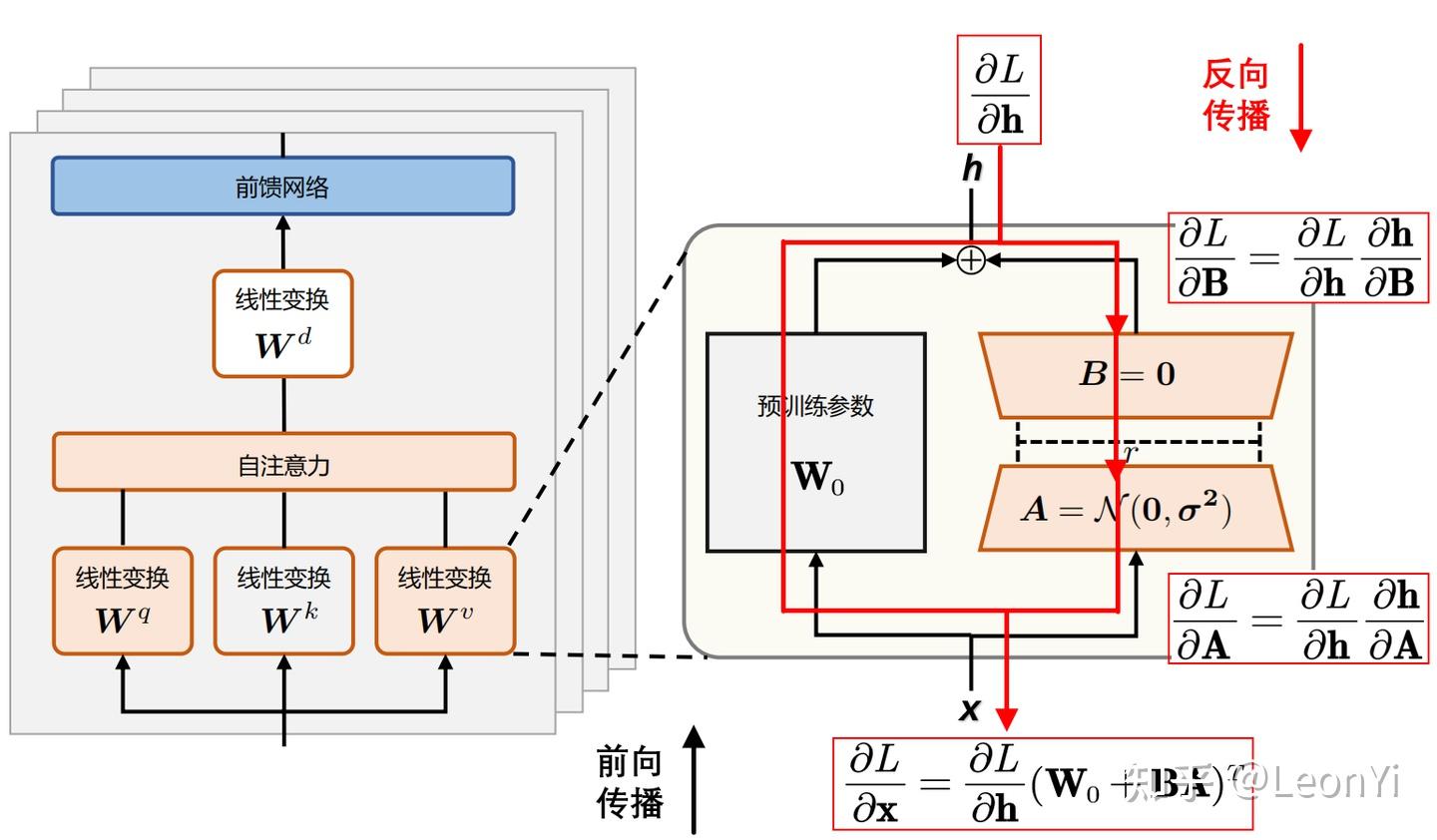
https://kexue.fm/archives/9590
增强模型推理能力的方法
- 推理时间扩展: 思维链提示、多数投票、Best-of-N
- 强化学习(RL): Deepseek R1 Zero
- SFT+RL: Deepseek R1
- 蒸馏: Deepseek R1 Distill
【LLM】增强大模型推理能力的四种范式_大模型的推理、微调、对齐、蒸馏-CSDN博客
大模型推理能力提升的一个技术总结 - 知乎
Agent
OpenAI提出的智能体五层级演进过程:
第一阶段,知识获取智能体。模型主要通过人机对话的方式进行信息交互与知识传递,表现为一种响应式的知识库,如ChatGPT的早期版本。(因此非推理大模型其实就是一种 RAG 系统,从训练的模型参数中检索世界知识;外置知识库的 RAG 系统效果不好,只是对大模型的拙劣模仿)
第二阶段,认知推理智能体。模型能力深化,能够处理复杂的认知任务,进行深度逻辑推理与抽象思考,从而胜任奥林匹克数学竞赛、科学研究推导等高级智力活动,成为增强人类智识的”智能助手”。如 OpenAI o3.
第三阶段,自主执行智能体(我们在这)。模型具备在真实或虚拟环境中自主完成任务的能力,如Claude Code。它不仅限于代码生成等单一指令,而是能够形成”感知-规划-行动-反馈”的闭环,展现出初级的能动性(Agency)。此阶段的能力在2025年2月于国际上达到了技术应用的引爆点。
第四阶段,创新发现智能体。模型的能力从任务执行跃迁至知识创造,能够生成新颖的、具有突破性的见解或成果,推动科学发现与技术创新,标志着其从”执行者”向”创新者”的角色转变,展现出真正的创造力。
第五阶段,协同多智能体系统。模型发展为复杂的生态系统,其中多个独立的智能体可以进行自主的分工、协作与协同进化。它们能够构建起虚拟的组织架构,跨领域合作,解决大规模、系统性的复杂问题。