目录
LLM RL
典型RL中智能体与环境的交互过程如下:
- 在 $ t $ 时刻,环境的状态为 $ s_t $ ,达到这一状态所获得的奖励为 $ r_t $
- 智能体观测到 $ s_t $ 与 $ r_t $ ,采取相应动作 $ a_t $
- 智能体采取 $ a_t $ 后,环境状态变为 $ s_{t+1} $ ,得到相应的奖励 $ r_{t+1} $
智能体在这个过程中学习,它的最终目标是:找到一个策略,这个策略根据当前观测到的环境状态和奖励反馈,来选择最佳的动作。
什么任务适合用 RL 做?
- 对于存在 Ground Truth 信号的任务(数学etc)来说,有一个明确的好答案标准、存在上限的任务适合 SFT ;难以标注(或定义)好答案,但很容易进行判别结果是否正确的任务,适合 RL。
- 对于不存在 Ground Truth 信号的任务(创作)来说,没有理想标准(或者标准更迭很快)、存在一些数据不一致性的场景适合 RL 。虽然我们不知道这个问题的最完美的答案是怎样的,但我们总能在当前的几个候选答案里找出最好的那一个。
RLHF
核心流程:
- 预训练:用大规模文本数据训练初始语言模型(LM)。
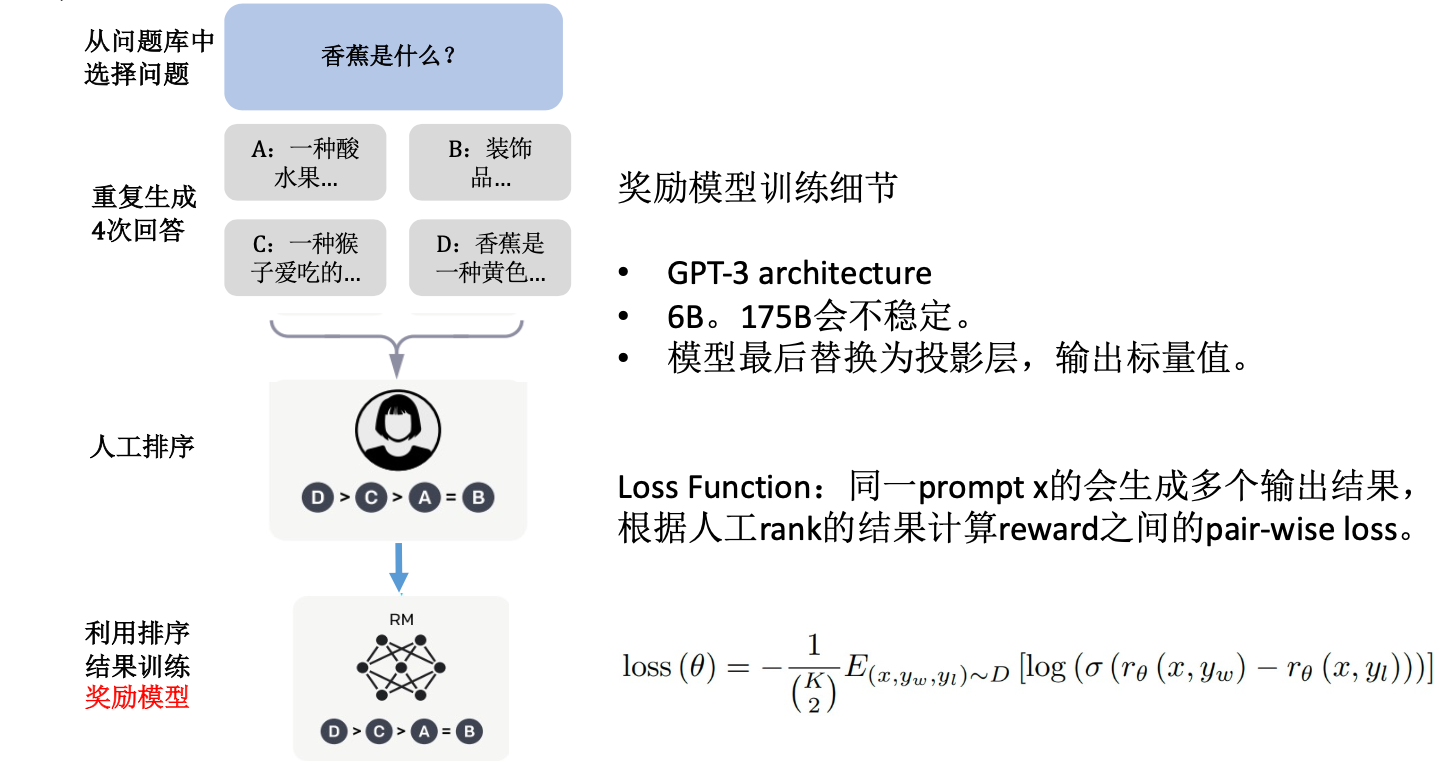
- 奖励模型训练:通过人类标注的偏好数据(如对多个回答排序),训练奖励模型(RM)。
- 强化学习微调:使用PPO等算法,以RM为奖励信号优化LM,使其生成更符合人类偏好的输出。
奖励模型
我们希望获得人类偏好的分布,x代表输入的prompt,两个不同的输出y1,y2,假设y1比y2好,这是个概率,我们希望最终的模型是完美的,每进一个x,能够打分:
p 表示在理想情况下,模型输出 $y_1$ 优于 $y_2$ 的概率。
r 是最优的(optimal)、无法直接获得的奖励函数。
这就是 Bradley-Terry模型。假设对于问题 x,奖励模型给回答 y1 打了3分,给回答 y2 打了1分。
那么,模型预测人类认为 y1 比 y2 好的概率就是:
这意味着,模型有88%的把握认为人类会选择 y1 而不是 y2。
- 对同一提示,标注员对多个模型生成的回答进行排序(如A > B > C),构造为三元组 $ (x, y_w, y_l) $ ,其中 $ y_w $ 是更优的回答。
- 我们通常使用最大似然估计(Maximum Likelihood Estimation)的原则来构建损失函数。通俗地说,就是“让已经发生的事情(即我们收集到的人类偏好数据)在模型看来,发生的概率最大”。对于一个偏好数据
(x, y_w, y_l),我们希望最大化模型预测它发生的概率,也就是最大化上面的 $P^(y_w \succ y_l\mid x)$。 - 在实践中,直接最大化概率的乘积(对于整个数据集)在计算上很困难,所以我们通常会:
- 取对数(Logarithm),将乘积问题变为加法问题,这不改变最优解。这就是对数似然(Log-Likelihood)。
- 将“最大化”问题转化为等价的“最小化”问题,只需在前面加一个负号。
- 这样,我们就得到了奖励模型最常用的损失函数(Loss Function)—— 负对数似然损失(Negative Log-Likelihood Loss)。
- 或者用sigmoid函数写作
- reward model通过SFT后的LLM加一层线性层去初始化
LLM 中主流的 RLHF 方向分为两大路线:
以 PPO 为代表的 On-Policy 路线:训练过程中,需要模型亲自参与”生成”来收集新的数据样本。
以 DPO 为代表的 Off-Policy 路线:训练过程中,不需要”在线”生成,更多依赖事先收集到的(或由别的策略产生的)数据进行离线学习。
https://mp.weixin.qq.com/s/S72LO26IsZ8AED8sQKIWnQ
https://zhuanlan.zhihu.com/p/675329917
从策略梯度算法到 PPO
1. 策略梯度
原始策略梯度算法 (REINFORCE / Vanilla Policy Gradient)奠定了后续所有算法的基础。
核心思想: 直接对策略本身进行建模和优化。如果一个动作序列(Trajectory)最终获得了很高的回报,那么我们就调整策略,让策略网络在遇到这些状态时,更有可能输出这些带来高回报的动作。反之亦然。
目标函数: 算法的目标是最大化期望总回报(Expected Total Reward)。我们用 $\theta$ 表示策略网络 $\pi_\theta$ 的参数,$\tau$ 表示一条完整的轨迹($s_0, a_0, r_0, s_1, a_1, r_1, \dots$),$R(\tau)$ 是这条轨迹的总回报。目标函数为:
这个公式的含义是,在当前策略 $\pi_\theta$ 下,采样很多轨迹,计算这些轨迹总回报的平均值,我们希望这个平均值越大越好。
梯度与损失函数: 目标函数 $J(\theta)$ 是通过与环境进行复杂的、随机的交互产生的,它不是一个关于 $\theta$ 的简单、可直接求导的函数。奖励信号来自环境,而不是来自模型内部。我们无法像在监督学习中那样,直接通过奖励对模型参数进行反向传播。直接对 $J(\theta)$ 求导很困难,因为期望的概率分布 $P(\tau; \theta)$ 也依赖于 $\theta$。通过“策略梯度定理”(Policy Gradient Theorem),我们可以得到一个可计算的梯度形式:
在实践中,为了减少方差,我们不会用整条轨迹的总回报 $R(\tau)$ 来评估时间步 $t$ 的动作 $a_t$,因为在 $t$ 时刻的动作并不会影响 $t$ 之前的奖励。因此,我们使用“未来回报总和”(Reward-to-go),即从当前时刻 $t$ 到轨迹结束的总回报 $R_t = \sum_{k=t}^{T} \gamma^{k-t} r_k$。
梯度更新就变成了:
为了使用梯度下降(最小化)来优化,我们构造一个损失函数,通常是目标函数的负数:
这个损失函数直观地告诉我们:如果 $R_t$ 是正的(未来回报高),就最小化 $-\log \pi_\theta$,即增大 $\log \pi_\theta$,也就是增大动作 $a_t$ 的概率;如果 $R_t$ 是负的(未来回报低),就减小动作 $a_t$ 的概率。
主要问题: 高方差 (High Variance)。$R_t$ 的值完全依赖于一次采样的结果,波动性非常大。可能某次采样中,一个不错的动作因为后续随机性导致了不好的结果,从而得到了负向更新。这种噪声使得训练过程非常不稳定,收敛缓慢。
2. Actor-Critic (AC)
Actor-Critic 旨在解决 REINFORCE 的高方差问题。
核心思想: 将策略梯度分成两个部分:
- Actor (演员): 策略网络 $\pi_\theta(a|s)$,负责选择动作,和 REINFORCE 中的策略网络一样。
- Critic (评论家): 价值网络 $V_\phi(s)$ 或 $Q_\phi(s,a)$,负责评估当前状态或状态-动作对的好坏,它的作用是为 Actor 的行为打分。
改进之处: AC 不再使用随机性很强的蒙特卡洛采样回报 $R_t$ 来作为权重,而是使用 Critic 网络给出的一个更稳定的价值评估。具体来说,我们引入优势函数 (Advantage Function) $A(s_t, a_t)$ 来取代 $R_t$。
优势函数的直观含义是:在状态 $s_t$ 下,采取动作 $a_t$ 比通常情况(平均水平 $V(s_t)$)要好多少。这比单纯的 $R_t$ 是一个更好的基准(Baseline),因为它减去了状态本身价值的干扰,只关注动作的相对好坏,进一步降低了方差。
目标与损失函数:
- Actor 的损失函数: 形式上和 REINFORCE 很像,只是用优势函数 $A(s_t, a_t)$ 替代了 $R_t$。在实践中,优势函数通常用 TD-error $\delta_t = r_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t)$ 来近似,因为它是一个对优势函数的无偏估计。
- Critic 的损失函数: Critic 的目标是准确地学习价值函数 $V_\phi(s)$。它通过最小化 TD-error 的均方误差来更新。
主要问题: 尽管降低了方差,但 Actor 的更新步长(学习率)非常敏感。如果某次更新的步子迈得太大,可能会导致策略突然变得很差,并且很难再恢复过来。学习过程仍然不够稳定。
3. TRPO
TRPO (Trust Region Policy Optimization)直接解决了 AC 算法中更新步长难以确定、策略容易“崩溃”的问题。
核心思想: 我们希望策略向好的方向更新,但又不希望新策略和旧策略偏离太远,以保证更新的稳定性。TRPO 将这个思想数学化,定义了一个“信赖域”(Trust Region),强制要求每次更新后的新策略都位于这个域内。
目标函数: TRPO 的目标函数是最大化一个“代理目标函数”(Surrogate Objective),它衡量了新策略 $\pi_\theta$ 相对于旧策略 $\pi_{\theta_{old}}$ 的改进程度。令概率比率 $\rho_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$。
这里的比率 $\rho_t(\theta)$ 是重要性采样(Importance Sampling)的权重,$\hat{A}_t$ 是优势函数的估计。
改进之处 (核心): TRPO 的精髓在于它不是直接最大化这个目标函数,而是把它变成一个带约束的优化问题:
这个约束使用 KL 散度(KL Divergence)来衡量新旧策略的差异,并要求这个差异不能超过一个很小的阈值 $\delta$。这保证了策略更新的平稳性,避免了灾难性的更新。
损失函数: TRPO 没有一个简单的损失函数。它是一个约束优化问题,需要用到共轭梯度法(Conjugate Gradient)等二阶优化方法来求解,计算非常复杂。
主要问题: 计算复杂且难以实现。TRPO 涉及复杂的二阶优化,与现代深度学习框架(如 TensorFlow, PyTorch)中常用的一阶优化器(如 Adam)不兼容,实现起来非常困难。
4. PPO
PPO (Proximal Policy Optimization) 的目标是实现 TRPO 的稳定更新思想,但使用更简单、易于实现的一阶优化方法。
核心思想: TRPO 的 KL 散度约束太复杂,我们能否直接修改目标函数,使得在优化这个函数时,就能自然地达到限制策略更新幅度的效果?PPO 通过“裁剪”(Clipping)来实现这一点。
目标函数/损失函数 (PPO-Clip): PPO 使用的目标函数从 TRPO 改进而来,创新地增加了裁剪机制。令概率比率 $\rho_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$。
这个公式是 PPO 的灵魂:
- $\text{clip}(\rho_t(\theta), 1-\epsilon, 1+\epsilon)$: 强制将概率比率 $\rho_t$ 裁剪到 $[1-\epsilon, 1+\epsilon]$ 的区间内($\epsilon$ 是一个超参数,如 0.2)。
- $\min(\dots, \dots)$:
- 当优势 $\hat{A}_t > 0$ 时(即这是一个好动作),目标函数变为 $\min(\rho_t \hat{A}_t, (1+\epsilon)\hat{A}_t)$。这意味着 $\rho_t$ 的增长被限制在 $1+\epsilon$,防止策略更新过于激进,过分地增加这个好动作的概率。
- 当优势 $\hat{A}_t < 0$ 时(即这是一个坏动作),目标函数变为 $\max(\rho_t \hat{A}_t, (1-\epsilon)\hat{A}_t)$(因为 $\hat{A}_t$ 是负数,min 相当于 max)。这限制了 $\rho_t$ 的减小不能低于 $1-\epsilon$,防止策略为了避免一个坏动作而过度改变。
通过这种方式,PPO 将 TRPO 的硬约束(KL散度)变成了一种软约束,直接体现在了目标函数中。这个 $L^{CLIP}(\theta)$ 可以直接用 Adam 等一阶优化器进行最大化(或者最小化其负数)。
改进之处: PPO 在实现 TRPO 稳定性的同时,大大简化了算法的实现难度和计算开销,使其成为当前最流行、最常用的强化学习算法之一。
动手学强化学习
Spinning Up in Deep RL
https://zhuanlan.zhihu.com/p/614115887
PPO
概念与组成
当下的状态和动作会影响到未来的状态和动作,进而影响到未来的整体收益。因此要将未来的收益纳入当前的考虑。因此 $ R_t = r_t + \gamma R_{t+1} $
其中:
- $ R_t $ : t 时刻的(预期)总收益(return),注意这个收益蕴涵了”即时”和”未来”的概念
- $ r_t $ : t 时刻的即时收益
- $ R_{t+1} $ : t+1 时刻的(预期)总收益。而 $ R_{t+1} $ 对 $ R_t $ 来说就是”未来”。
- $ γ $ :折扣因子。它决定了我们在多大程度上考虑将”未来收益”纳入”当下收益”。
在 t 时刻,模型产出token $a_t$ 对应着的即时收益为 $r_t$,总收益为 $R_t$ ,模型的状态从 $s_t$ 变为$s_{t+1}$
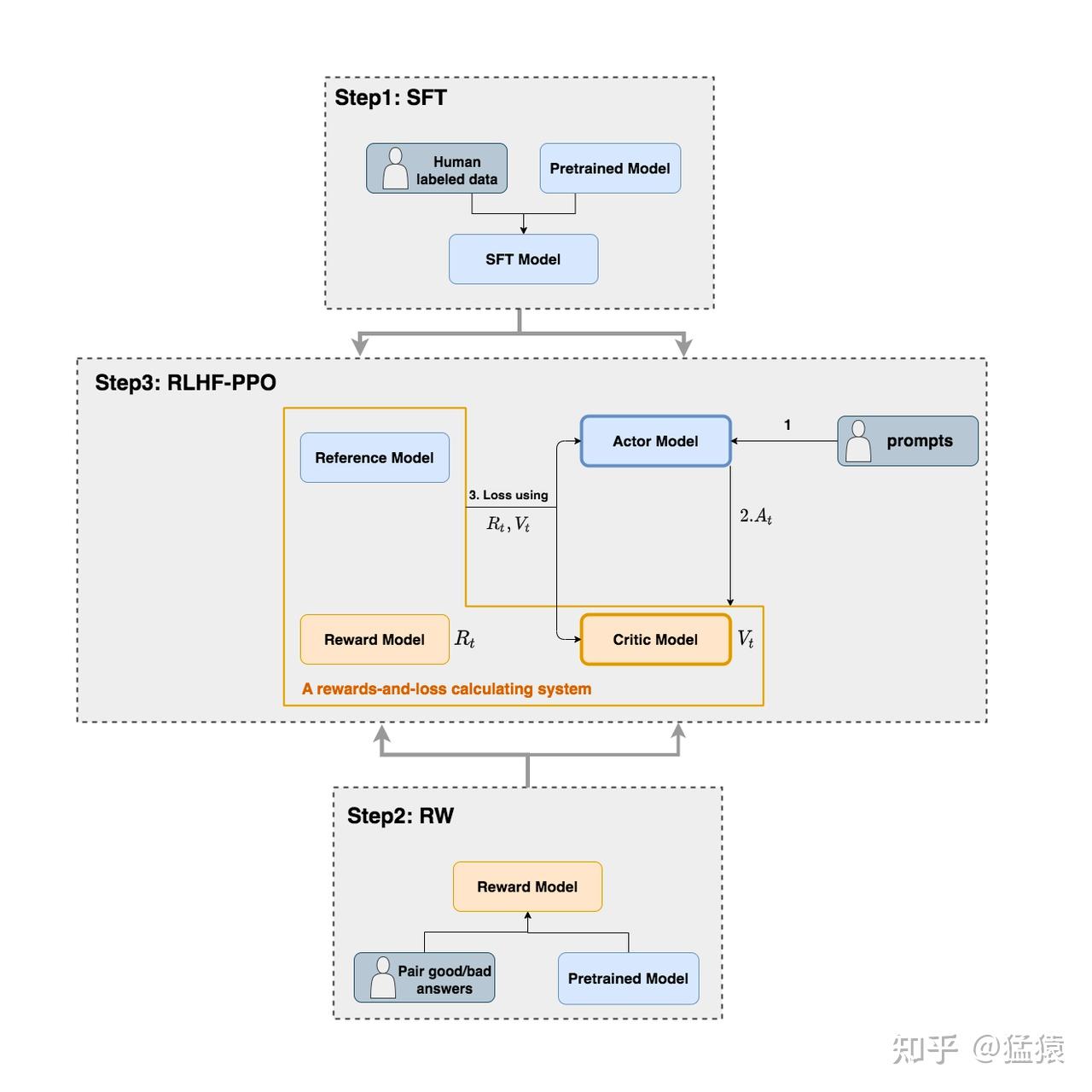
如上图,在RLHF-PPO阶段,一共有四个主要部分,分别是:
- Actor Model (Policy Model):演员模型,这就是我们想要训练的目标语言模型
- Reward Model:奖励模型,”裁判”,它的作用是计算最终收益 $ r(x, y) $ 。参数冻结
- Critic Model (Value Model):评论家模型,”教练”,它的作用是预估某一时刻的总收益 $ V(s_t) $ 。实际上只有模型响应生成结束后才能由 Reward Model 判断对错,因此训练过程奖励是稀疏的, Critic Model 就是要把稀疏的奖励信号换算成每一步的收益,方便训练。需更新参数
- Reference Model:参考模型,就是保存一个没有经过 RL 的模型作为参考。它的作用是在RLHF阶段给语言模型增加一些”约束”,防止语言模型训歪(很容易偏离原本的分布,朝不受控制的方向更新,效果可能越来越差)。参数冻结
(四大天王有五个不是常识吗)Generalized Advantage Estimation (GAE):用于计算优势函数 $\hat{A}_t$,核心作用是在方差(Variance)和偏差(Bias)之间做权衡,平滑 TD-error。它不是在计算收益,而是在计算“这一步动作比平均水平好多少”。
训练流程
- 策略模型 (Policy LM) 根据上下文 $x$ (或 $s$) 生成完整的回应 $y$。
- 奖励模型 (Reward Model) 评估这些回应,并为其打出奖励分数 $r(x,y)$。
- 广义优势估计 (GAE) 结合奖励分数和价值模型的估计值,来计算:
- 每个词元 (token) 的回报 (Returns) $R_t$(用于训练价值模型)。
- 每个词元选择的优势 (Advantages) $\hat{A}_t$(用于训练策略语言模型)。
- 更新价值模型 (Value Model),以提升回报 $R_t$ 和优势 $\hat{A}_t$ 估计的准确性。
- 使用优势值更新策略语言模型 (Policy LM),以优化其生成回应的能力。

*: 图中 SFT model 指 reference model
公式推导
1. 确立总目标函数
我们从 RLHF 的最终优化目标出发。这是一个理论上的期望,我们希望最大化它:
即
这个目标是针对完整生成序列的,无法直接用于 PPO 这种按步更新的算法。实际上因为不可能用整个序列计算 KL散度(指数时间复杂度),我们将KL分到每个token计算一次,再加和。
2. 将总目标分解为每一步的奖励信号
为了让 PPO 算法能够“理解”这个目标,我们必须将其分解为在每个时间步(time-step)t 都能获得的奖励信号 $r_t$。
其中
现在,PPO 算法的任务就变成了:最大化这些分步奖励 $r_t$ 的累积期望值。至此,我们已经把复杂的总目标转化为了一个标准的强化学习问题。
3. 应用策略梯度定理
现在的问题是:如何更新策略 $\pi_\theta$ 来最大化累积的 $r_t$?这里,我们祭出核心工具——策略梯度定理。该定理告诉我们,最大化奖励的梯度方向是:
这个公式的直观含义是:用一个“权重”来决定是否要增加动作 $(a_t|s_t)$ 的概率。
4. 用优势函数作为“权重”
理论证明,最好的“权重”是优势函数 (Advantage Function) $\hat{A}_t$,因为它能减小方差,让训练更稳定。优势函数的计算完全基于第二步中定义的奖励信号 $r_t$。
于是,我们的策略梯度更新公式就具体化为:
$\hat{A}_t$ 中已经包含了来自总目标函数的所有信息(奖励模型分数和KL惩罚)。
深入理解 GAE (Generalized Advantage Estimation)
作为 PPO 中的“定海神针”,GAE 的核心作用不是背公式,而是理解它如何解决 RL 中最痛苦的矛盾:方差(Variance)与偏差(Bias)的权衡。
1. 为什么需要 GAE?(通俗解释)
想象你在玩《黑神话:悟空》打 Boss。你做了一个“闪避”动作,结果 30 秒后你被打败了。
- 蒙特卡洛(MC)视角:因为你最后死了,所以 30 秒前的那个“闪避”是坏动作。—— 这叫高方差:中间发生了太多随机的事,把那个动作的功劳给淹没了。
- TD(时序差分)视角:闪避完那一刻,你血条没掉,看起来挺好。—— 这叫高偏差:你只看眼前,可能忽略了这个动作其实导致你体力耗尽,间接导致了死亡。
GAE 的作用就是当一个“平衡大师”。它通过一个参数 $\lambda$,让你自己决定:我到底是多信眼前的评估(Critic),还是多信长远的结果(Reward)。
2. 核心原理:从 TD-error 开始
在 LLM 的 PPO 训练中,我们每一步都会产生一个 TD-error ($\delta_t$)。它是 GAE 的基石。
- $r_t$:当前 token 的即时奖励(在 LLM 中通常是 KL 惩罚,或者是最后一个词给的 RM 分数)。
- $V_t$:Critic 模型对当前状态价值的预估。
- $\delta_t$ 的含义:“现实比预期好多少”。
3. 公式推导:步步为营
我们要计算的是优势函数 $A_t$。如果我们往后看 $k$ 步,会有不同的估算方式:
- 1 步看(TD):$A_t^{(1)} = \delta_t$
- 2 步看:$A_t^{(2)} = \delta_t + \gamma \delta_{t+1}$
- $\infty$ 步看(MC):$A_t^{(\infty)} = \delta_t + \gamma \delta_{t+1} + \gamma^2 \delta_{t+2} + \dots$
GAE 的天才想法是:我不选任何一个特定的 $k$,我把所有步数的估算做一个加权平均!权重系数就是 $\lambda$。
经过代数化简,我们得到了最终的 GAE 核心公式:
递归形式(代码里最常用的):
4. 关键参数 $\lambda$ 的奥秘
GAE 实际上是在这两个极端之间滑动的拨杆:
- 当 $\lambda = 0$:
- $\hat{A}_t = \delta_t = r_t + \gamma V(s_{t+1}) - V_t$。
- 这就是纯 TD(0)。低方差(只受下一步影响),但高偏差(极度依赖 Critic 准不准)。
- 当 $\lambda = 1$:
- $\hat{A}_t = \sum_{l=0}^{\infty} \gamma^l \delta_{t+l}$。
- 展开后你会发现,这其实就是“实际总收益 - 预测价值”。
- 这就是纯 MC(蒙特卡洛)。无偏差(用真实回报说话),但高方差(随机性大到无法训练)。
在工业界(如 PPO 训练 LLM),通常设置 $\gamma = 0.99$ 和 $\lambda = 0.95$。这被证明是一个“甜点区”,既能让模型收敛,又能保证学到的动作是有远见的。
5. 总结:GAE 在代码里是怎么跑的?
如果你去写代码实现,逻辑通常是从后往前倒着算:
- 先算出最后一个 token 的 $\delta_T$。
- 利用递归公式 $\hat{A}_t = \delta_t + (\gamma \lambda) \hat{A}_{t+1}$。
- 因为 $t+1$ 时刻的优势已经算出来了,所以可以算出 $t$ 时刻。
- 最后,我们会对算出来的整组 Advantage 做一个 Normalization(减均值除方差),这能让训练梯度更稳定。
5. 构建 actor model 的损失函数
在深度学习框架中,我们习惯于通过梯度下降最小化一个损失函数。而策略梯度 $\nabla_\theta J(\theta)$ 是我们需要上升 (ascend)的方向。
我们只需简单地在梯度表达式前加上一个负号,就可以将其转换为一个损失函数:
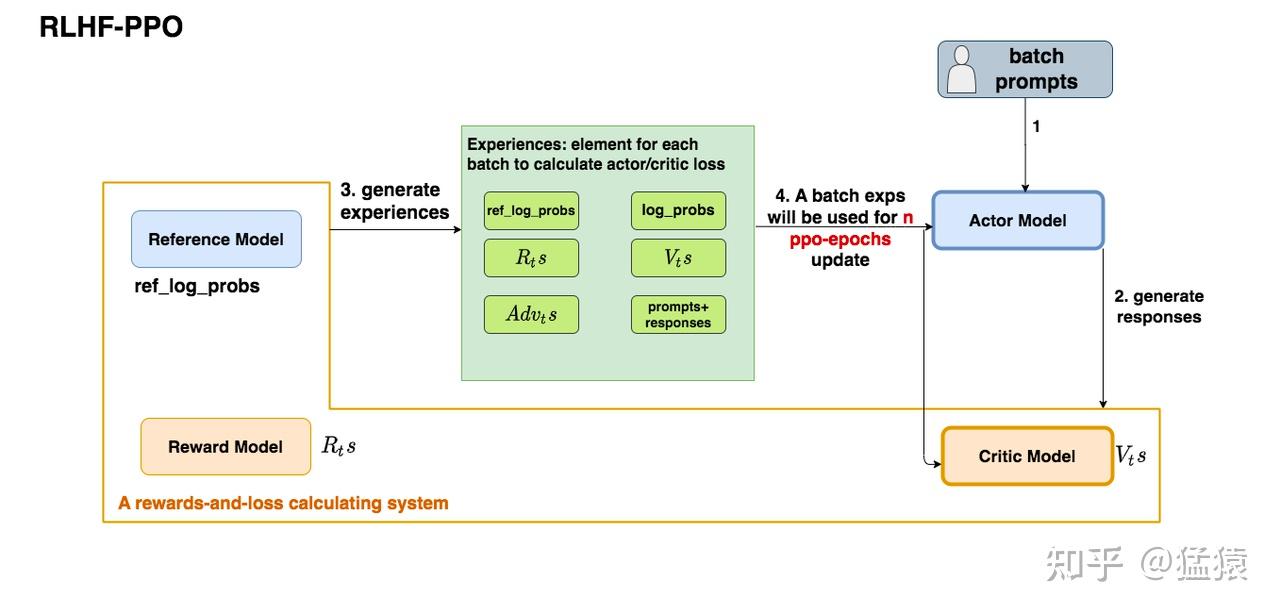
而如果我们想让一个batch的经验值被重复使用ppo_epochs次,等价于我们想要Actor在这个过程中,模拟和环境交互ppo_epochs次,每次都能吐出一些新数据出来。我们只要尽量保证每次更新后的 $Actor_{new}$ 能模仿最开始的那个 $Actor_{old}$(这里涉及“重要性采样”):
这个公式从直觉上也可以理解成:在Actor想通过模拟交互的方式,使用一个batch的经验值更新自己时,它需要受到真正吃到batch的那个时刻的Actor的约束,这样才能在有效利用batch、提升训练速度的基础上,保持训练的稳定。
另外,PPO-clip还加入了Clip机制用来限制策略更新幅度,防止新策略与旧策略差异过大。
其中 $\rho_t(\theta)=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)}$,$ \epsilon $ 是剪切阈值(如0.2), $ \hat{A}_t $ 是优势函数估计。
在实际计算时,我们用一批采样数据的均值来代替期望 $\mathbb{E}$,得到最终用于代码实现的 actor_loss。
6. 构建 critic model 的损失函数
以上我们用算出来的 $r_t, V_t$ 更新了 actor model 的参数,其实这些还需要用来训练 critic model:
每次迭代用 MSE 计算 critic model 的预测和 GAE 给出的预测的差值更新 critic model,让它对收益的估计越来越准确。每个 batch 更新,batch 内 ppo_epochs 之间不变。
Critic Loss 也采用了裁剪机制来限制值函数的更新幅度,以防止训练过程中的不稳定。
其中:
- $V_\phi(s_t)$:当前值网络对状态 $s_t$ 的估计。
- $R_t$:目标回报(实际回报)。
- $V_\phi(s_t)^{\text{clipped}}$:裁剪后的值函数。它的计算方式如下:其中,$V_\phi(s_t)^{\text{old}}$ 是前一次的估计值,$\epsilon$ 控制裁剪的范围。
PPO相比传统策略梯度方法(如TRPO)有哪些改进?
改进:
- 简化实现:PPO通过剪切(Clip)替代TRPO的复杂约束优化,避免计算二阶导数。
- 数据效率:支持多次使用同一批数据更新策略(通过重要性采样)。
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 - 知乎
Reinforcement Learning With Human Feedback (RLHF) with Proximal Policy Optimization (PPO)
https://zhuanlan.zhihu.com/p/7461863937
https://zhuanlan.zhihu.com/p/19223907990
离线RL-DPO
核心思路:对于同一个问题(prompt),有一个好答案/坏答案的数据对(pair-wise data),让策略函数(也就是大模型)离好答案的分布概率更近,离坏答案的分布概率更远。
DPO 原始论文中的概括的流程如下:
构建偏好数据集:对于每一个提示(prompt)$x$,从参考策略 $\pi_{\mathrm{ref}}(\cdot \mid x)$ 中采样生成两个补全(completion)$y_1$ 和 $y_2$。然后,根据人类的偏好对它们进行标注,从而构建一个离线的偏好数据集 $\mathcal{D} = \{ (x^{(i)}, y_w^{(i)}, y_l^{(i)}) \}_{i=1}^N$。其中 $y_w$ 代表更受偏好的回答(winner),$y_l$ 代表较差的回答(loser)。
优化模型:在给定的参考策略 $\pi_{\mathrm{ref}}$、数据集 $\mathcal{D}$ 和期望的超参数 $\beta$ 的条件下,通过最小化损失函数 $\mathcal{L}_{\text{DPO}}$ 来优化语言模型 $\pi_\theta$。
DPO实现:
- 假设偏好数据服从Bradley-Terry模型,通过极大似然估计直接优化策略: 其中 $ \pi_{\text{ref}} $ 是参考策略(如初始LM), $ \beta $ 控制KL正则化强度。
DPO vs SFT
虽然 DPO 只是在使用现成的数据集中的 $(x, y_w, y_l)$ 这种数据对而不是像 PPO 让策略与环境交互获得反馈,但它和 SFT 的底层逻辑完全不同。
- SFT (监督微调):它是“模仿者”。
- 目标是让 $\pi(y_w|x)$ 的概率最大化。
- 它只看“正确答案”,不看“错误答案”。如果你把 $y_l$ 喂给 SFT(做负例微调),由于交叉熵损失的特性,它只会盲目降低 $y_l$ 的概率,而不知道该把它降到多少。
- DPO (直接偏好优化):它是“裁判员”。
- 它不仅要提高 $y_w$ 的概率,还要拉大 $y_w$ 和 $y_l$ 之间的相对差距。
- 关键公式差异:注意 $\mathcal{L}_{DPO}$ 中的 $\frac{\pi}{\pi_{ref}}$,它引入了一个参考模型。DPO 不是在学绝对的概率,而是在学:“相对于参考模型,我应该在多大程度上把好答案的权重提上来,把坏答案的权重压下去。”
但也因为没有与环境交互采样获得新数据,离线RL不能让模型学会探索环境,只能是学习数据集中已知的知识。
DPO vs PPO
为什么没有新采样也能学得好?
“没有新采样、没有新 Reward”是 DPO 的离线(Off-policy)特性。
在 PPO 中,我们需要一个显式的 Reward Model(RM)来给每一步打分。而 DPO 的天才之处在于:它证明了 最优策略 $\pi^*$ 与 奖励函数 $r(x, y)$ 之间存在数学上的闭式解映射。
简单来说:模型本身就是奖励模型。
- PPO:依赖奖励模型提供标量奖励,通过强化学习更新策略。
- DPO:直接将偏好数据映射到策略优化目标,通过隐式奖励建模绕过显式RM训练。 当你增加 $y_w$ 的概率并降低 $y_l$ 的概率时,你实际上是在隐式地构造一个奖励面。
- 这种“不采样”的代价:分布偏移(Distribution Shift)。DPO 极度依赖偏好数据集的质量。如果数据集里没见过的表达方式,DPO 永远学不会。它只能在已有的“池子”里重新分配概率。模型在训练集上能分清 $A > B$,但在推理时,模型可能会生成一个训练集里从未出现的 $C$。此时模型对 $C$ 的评价(隐式 Reward)可能是完全错乱的。
这也是为什么现在工业界开始流行 Iterative DPO (迭代式 DPO):
- 用当前的 DPO 模型采样出一些新回复。
- 用一个更强的模型(比如 GPT-4o 或专门的 RM)给这些新回复标注偏好。
- 把新数据喂给模型再跑一次 DPO。
这本质上就是把 DPO 变成了“带采样的在线强化学习”,从而弥补它不采样的短板。
不同 Epoch 学的内容一样吗?
这涉及到 梯度(Gradient)的动态变化。
虽然数据没变,但随着 Epoch 增加,模型的参数 $\theta$ 在变,这意味着:
- 梯度权重在变:看 DPO 的损失函数公式,它外面套了一个 $\sigma$(Sigmoid)。
- 如果模型已经能很好地区分 $y_w$ 和 $y_l$(即差值很大),Sigmoid 会进入饱和区,梯度会变得非常小——模型会说:“这题我会了,不用再深究。”
- 如果模型分不清(差值很小),梯度会非常大——模型会说:“这题我得重点学。”
- KL 散度的约束:公式里的 $\beta$ 像一根橡皮筋,拉着新模型不要跑离 $\pi_{ref}$ 太远。随着 Epoch 增加,模型在尝试突破约束去拉大 $y_w/y_l$ 差距,而 $\pi_{ref}$ 始终在那里起稳定作用。
比喻:SFT 像是背课文,你背 10 遍也是在背那几句话;而 DPO 像是做“找不同”,第一遍你可能只发现大区别,第二遍你会开始注意微小的特征差异来拉开两者的评分。
如何初始化策略模型
在实践中,研究者们更倾向于重用公开可用的偏好数据集,而不是自己生成样本并收集人类偏好。由于这些公开的数据集通常是使用一个经过监督微调(SFT)的模型 $\pi_{\text{SFT}}$ 进行采样的,因此,当 $\pi_{\text{SFT}}$ 模型可用时,我们通常将参考策略初始化为 $\pi_{\mathrm{ref}} = \pi_{\text{SFT}}$。
然而,当生成数据集的 $\pi_{\text{SFT}}$ 模型不可用时,我们会通过最大化更优补全 $(x, y_w)$ 的对数似然来初始化参考策略 $\pi_{\mathrm{ref}}$,即:
这个过程有助于缓解那个无法获得的、真实的参考分布与 DPO 实际所使用的参考策略 $\pi_{\mathrm{ref}}$ 之间的分布偏移问题。
为什么有时候DPO只需要一个模型,表现(收敛性、易训性)却比PPO好?
- 奖励函数只传递单一维度,但好坏是多维度决定的;reward function过度压缩信息,dpo把两个信息挤压在一起,传输效率更好
- The Bitter Lesson:寻找捕捉复杂性的元方法,靠数据量 Scale Up 取胜而不是人工引入新的机制(Reward Model)
https://zhuanlan.zhihu.com/p/721073733
https://www.bilibili.com/video/BV1dWB2Y4EcG/?p=9
Deepseek R1 与 GRPO

Deepseek R1厉害在哪?
Deepseek R1 Zero 成功解决了不依赖大量标注 reasoning 数据来教授LLM一步步思考的挑战,仅通过RL让模型自己发现长思考的技能。
Deepseek不使用可能引起 reward hacking 的复杂 reward model,而是使用基于规则的、可以自动验证的 reward model ,自动验证避免了人工或LLM验证引起的错误、偏差或幻觉。
GRPO
GRPO 由 PPO 改进而来:它不是使用价值模型来估计优势计算的基线,而是为每个输入对多个输出进行采样,并使用每组内的平均奖励作为基线。这意味着,如果为数学问题生成 64 个输出,其中一个获得 0.9 的奖励,而组平均值为 0.7,则该解决方案将获得 0.2 的正优势。这种基于组的方法提供了一种自然的方法来确定输出是好于还是差于平均值,而无需单独的值模型进行预测。最终,模型学会了纠正自身错误的能力,例如“等等,我注意到上一步有错误…”这里的优势会更高。
个人认为它的核心思想在于 the bitter lesson,利用多次采样这种简单粗暴的方法去掉了精心设计的价值模型所引入的偏差

DeepSeek R1 and R1-Zero Explained
GSPO等
https://zhuanlan.zhihu.com/p/1933217003654586554
Reward Hacking
- 如何避免?
- 对于针对系统设计的 reward hacking,将 Agent 沙盒化,不让它接触到reward function
- 多种奖励的组合。结合不同类型的奖励可能使其更难被 hacking
- 像 Deepseek R1 不使用可能引起 reward hacking 的复杂 reward model,而是使用基于规则的、可以自动验证的 reward model