LLM KBQA是一个行将就木的方向,它其实和RAG(检索增强生成)关系密切,这里目前仅列出KBQA相关的工作。
Pangu
Don’t Generate, Discriminate: AProposal for Grounding Language Models to Real-World Environment
论文中提出的方法论,即Pangu框架,是一个用于将语言模型与现实世界环境相结合的通用框架。该框架的核心思想是利用语言模型的判别能力来评估由符号代理生成的候选计划。
Pangu框架工作流程
- 初始化:定义一个初始计划集 _P_0,可能为空。
- 候选计划生成:符号代理在每一步与环境交互,基于当前计划生成新的候选计划集 _Ct_。
- 计划评估:语言模型对每个候选计划进行评分,选择得分最高的前 K 个计划作为下一步的候选。
- 终止检查:如果在当前步骤中没有找到比前一步骤更好的计划,则终止搜索。
- 返回结果:返回评分最高的计划作为最终结果。

BYOKG
BRING YOUR OWN KG: Self-Supervised Program Synthesis for Zero-Shot KGQA
BYOKG(Bring Your Own Knowledge Graph)是一个通用的基于大语言模型的知识图谱问答系统,能够操作任何知识图谱,并且不需要人类标注的训练数据。BYOKG的设计目的是在一天之内准备好使用。它的的灵感来自于人类通过探索来理解未见知识图谱中的信息的能力,例如从随机节点开始,检查相邻节点和边的标签,并结合他们的先验世界知识进行理解和问答。BYOKG的评分机制参考了上面提到的Pangu框架。
方法论:
- 探索模块:随机探索KG以收集查询程序示例
- 自然语言查询生成:利用LLM生成每个探索到的程序对应的自然语言问题,以获得探索语料库,枚举KG上可能被查询的程序集
- 自底向上推理:使用探索语料库来执行自下而上的推理过程,通过检索和评分机制,选择最有可能回答输入问题的程序并执行
核心技术:
- 使用least-to-most (L2M)提示词策略,即将复杂的问题分解为一系列更简单的子问题,再为每个子问题生成一个自然语言问题。在生成每个子问题的问题时,将之前所有更简单子问题的问题和解决方案作为上下文提示词提供给LLM。改进多跳程序的生成,以生成复杂的问题
- 使用逆一致性重排技术,即对于给定的输出(如生成的问题或查询程序),LLM会生成一系列候选序列,再对于每个候选序列,构建一个逆任务,即给定输出序列,预测原始的输入序列。使用LLM来评分每个候选序列完成逆任务的可能性,并根据这些评分对候选序列进行重排,选择最有可能正确反映原始输入的序列。
实验数据集:
- 小尺度知识图谱MoviesKG——对应的问答数据集MetaQA
- 大尺度知识图谱Freebase——对应的问答数据集GrailQA
CHATKBQA
CHATKBQA: A GENERATE-THEN-RETRIEVE FRAMEWORK FOR KNOWLEDGE BASE QUESTION ANSWERING WITH FINE-TUNED LARGE LANGUAGE MODELS
ChatKBQA 是一个基于微调的大型语言模型的生成-检索(Generate-then-Retrieve)知识库问答框架。
方法论:
- 该框架首先需要通过指令微调技术对开源LLM进行高效的微调。
- 微调后的LLM用于将自然语言问题转换为候选逻辑形式。
- 然后,通过无监督检索方法检索这些逻辑形式中的实体和关系,并将其替换为知识库中相应的实体和关系。
- 最终,将逻辑形式转换为SPARQL查询,以便在知识库上执行并获取答案。
核心技术:
使用生成-检索(Generate-then-Retrieve)技术:
- 首先使用微调后的LLM根据自然语言问题生成许多候选逻辑形式。
- 然后,通过无监督检索方法检索这些逻辑形式中的实体和关系,使用Top-K选择策略选择知识库中对应的实体和关系,并将其替换为知识库中相应的实体和关系,以得到最终SPARQL语句,执行后获得答案。
数据集:
WebQuestionsSP (WebQSP):包含4,737个自然语言问题及其对应的SPARQL查询。
ComplexWebQuestions (CWQ):包含34,689个自然语言问题及其对应的SPARQL查询。
这两个数据集都基于Freebase知识库构建
KB-BINDER
Few-shot In-context Learning for Knowledge Base Question Answering
KB-BINDER利用大型语言模型(如Codex)通过模仿一些示例来为特定问题生成逻辑形式草稿。然后,KB-BINDER使用BM25分数匹配在知识库上绑定生成的草稿,使其成为可执行的逻辑形式。
方法论:
KB-BINDER利用大型语言模型(LLM)生成初步逻辑形式作为草稿。草稿不一定可执行,因为它是在没有明确限制在候选词汇表和知识图结构的情况下由LLM生成的。然而,通过上下文提示的示范,草稿可以以语义上合理的方式揭示问题中提到的实体之间的结构关系。生成的草稿可以简化检索真实实体和关系所需的搜索空间。然后,通过BM25将这些实体和关系找到schema中最相似的实体和关系,以此组装出真的可执行的查询。
数据集:
- GrailQA: 这是一个多样化的KBQA数据集,构建在Freebase之上,覆盖了32,585个实体和3,720种关系,涵盖86个不同的领域。它旨在测试KBQA模型在不同级别的泛化能力,包括I.I.D.(独立同分布)、组合型和零样本。
- GraphQA: 这也是一个多样化的数据集,通过从图查询进行句子级别的释义来构建,评估模型在组合泛化方面的表现。
- WebQSP: 包含来自WebQuestions的问题,这些问题可以通过Freebase回答。它测试了模型在简单问题上的i.i.d.泛化能力。
- MetaQA: 由WikiMovies数据集衍生出的电影本体,包含三组不同难度级别的问答对。它评估了模型在特定领域内的效能,特别是多跳推理能力。
Interactive-KBQA
Interactive-KBQA: Multi-Turn Interactions for Knowledge Base Question Answering with Large Language Models
这是一个通过与知识库(KBs)直接交互生成逻辑形式的框架。在此框架内开发了三个通用的API用于KB交互。对于每种类型的复杂问题,通过few-shot示例来指导LLMs进行推理过程。
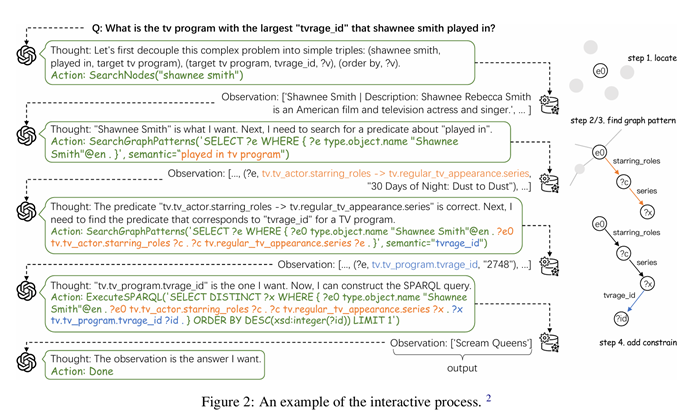
方法论
为了支持基于语义解析的 KBQA 方法,设计了以下三种工具来识别元素和适当的图模式:
- SearchNodes(name):在 KB 中搜索给定表面名称的节点,主要用于实体链接。
- SearchGraphPatterns(sparql, semantic):旨在识别 KB 中重要的图谓词,根据语义参数引导。
- ExecuteSPARQL(sparql):允许直接执行任意 SPARQL 查询,确保了极大的灵活性。
给定问题 _Q_,首先构建提示文本: Prompt={Inst, E, Q} 其中,Inst 包括工具描述、工具使用和交互格式。_E_ 是一组示例,每个问题类型手动注释两个完整的示例。
在每一轮 _T_中,让 LLM 基于提示和交互历史 _H_ 生成一个动作:
_aT_=LLM({Prompt, H})
_H_\={_c_0,_a_0,_o_0,…,_cT_−1,_aT_−1,_oT_−1} 其中 _c_ 表示中间思考过程,_a_ 是的三种工具的一种,_o_ 是执行动作的结果。
通过 Interactive-KBQA 方法,使注释推理过程变得更加简单。在 LLM 生成不合理动作时,可以人工进行纠正,并将其纳入生成下一轮动作的消息中。
数据集:
- WebQuestionsSP (WebQSP)
- ComplexWebQuestions (CWQ)
- KQA Pro: 这是一个大规模的数据集,设计用于在 Wikidata 知识库上进行复杂问题回答。它包含了多种复杂问题类型,如计数(Count)、查询属性(Query Attribute)、查询属性限定词(Query Attribute Qualifier)等。
- MetaQA
FlexKBQA
FlexKBQA: A Flexible LLM-Powered Framework for Few-Shot Knowledge Base Question Answering
- FlexKBQA首先利用收集到的结构化查询模板从知识库中采样大量程序(例如S-expressions),然后使用LLMs将这些程序转换为连贯的自然语言问题。通过生成这些程序-问题对,它们作为微调轻量级模型的宝贵资源。
- 为了弥补合成数据和真实用户查询之间的潜在分布差异,引入了执行引导的自训练(EGST)方法,利用微调后的轻量级模型主动注释真实用户查询。
- 通过迭代利用未标记的用户问题,这些注释的查询随后作为宝贵的训练数据,使模型能够自我改进。